Dijkstra(O(mlogn))
算法叙述
有了链式前向星,再来看Dijkstra算法,我们关注算法的第3)步,对和x直接相邻的点进行更新的时候,不再需要遍历所有的点,而是只更新和x直接相邻的点,这样总的更新次数就和顶点数n无关了,总更新次数就是总边数m,算法的复杂度变成了O(n²+m),之前的复杂度是O(n²),但是有两个n²的操作,而这里是一个,原因在于找d值最小的顶点的时候还是一个O(n)的轮询,总共n次查找。那么查找d值最小有什么好办法呢?
数据结构中有一种树,它能够在O(log(n))的时间内插入和删除数据,并且在O(1)的时间内得到当前数据的最小值,这个和我们的需求不谋而合,它就是最小二叉堆(小顶堆),具体实现不讲了,比较简单,可以参考堆排序。
在C++中,可以利用STL的优先队列(priority_queue)来实现获取最小值的操作,这里直接给出利用优先队列优化的Dijkstra算法的类C++伪代码(请勿直接复制粘贴到C++编译器中编译执行),然后再进行讨论:
注释1:初始化s到i的初始最短距离,d[s] = 0
注释2:q即优先队列,这里略去声明是为了将代码简化,让读者能够关注算法本身而不是关注具体实现,push是执行优先队列的插入操作,插入的数据为一个二元组(d[u], u)
注释3:执行优先队列的获取操作,获取的二元组为当前队列中d值最小的
注释4:执行优先队列的删除操作,删除队列顶部的元素(即注释3中d值最小的那个二元组)
以上伪代码中的主体部分竟然没有任何注释,这是因为我要用黑色的字来描述它的重要性,而注释只是注释一些和语法相关的内容。
详细讲解
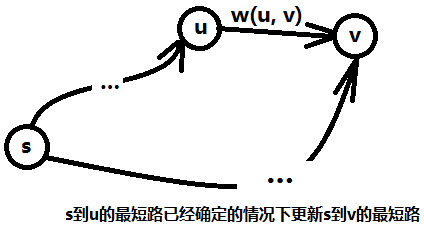
主体代码只有一个循环,这个循环就是遍历了u这个结点的边链表,其中e为边编号,edge[e].w即上文提到的w(u, v),即u ->v 这条边的权值,而d[u] + w(u, v) < d[v]表示从起点s到u,再经过(u,v)这条边到达v的最短路比之前其它方式到达v的最短路还短,如图二-4-1所示,如果满足这个条件,那么就更新这条最短路,并且利用path数组来记录最短路中每个结点的前驱结点,path[v] = u,表示到达v的最短路的前驱结点为u。
时间复杂度分析以及Dijkstra算法适用范围说明
补充一点,这个算法求出的是一棵最短路径树,其中s为根结点,结点之间的关系是通过path数组来建立的,path[v] = u,表明u为v的父结点(树的存储不一定要存儿子结点,也可以用存父结点的方式表示)。
考虑这个算法的复杂度,如果用n表示点数,m表示边数,那么优先队列中最多可能存在的点数有多少?因为我们在把顶点插入队列的时候并没有判断队列中有没有这个点,而且也不能进行这样的判断,因为新插入的点一定会取代之前的点(距离更短才会执行插入),所以同一时间队列中的点有可能重复,插入操作的上限是m次,所以最多有m个点,那么一次插入和删除的操作的平摊复杂度就是O(logm),但是每次取距离最小的点,对于有多个相同点的情况,如果那个点已经出过一次队列了,下次同一个点出队列的时候它对应的距离一定比之前的大,不需要用它去更新其它点,因为一定不可能更新成功,所以真正执行更新操作的点的个数其实只有n个,所以总体下来的平均复杂度为O((m+n)logm),而这个只是理论上界,一般问题中都是很快就能找到最短路的,所以实际复杂度会比这个小很多,相比O(n^2)的算法已经优化了很多了。
Dijkstra算法求的是正权图的单源最短路问题,对于权值有负数的情况就不能用Dijkstra求解了,因为如果图中存在负环,Dijkstra带优先队列优化的算法就会进入一个死循环,因为可以从起点走到负环处一直将权值变小。对于带负权的图的最短路问题就需要用到Bellman-Ford算法了。(这将会在下一个博客讲到)